
全国中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2021-12-06 来源:黑马程序员 浏览量:
MapReduce是一种编程模型,用于处理大规模数据集的并行运算。使用MapReduce执行计算任务的时候,每个任务的执行过程都会被分为两个阶段,分别是Map和Reduce,其中Map阶段用于对原始数据进行处理,Reduce阶段用于对Map阶段的结果进行汇总,得到最终结果,这两个阶段的模型如下图所示。

MapReduce编程模型借鉴了函数式程序设计语言的设计思想,其程序实现过程是通过map()和reduce()函数来完成的。从数据格式上来看,map()函数接收的数据格式是键值对,产生的输出结果也是键值对形式,reduce()函数会将map()函数输出的键值对作为输人,把相同key值的value进行汇总,输出新的键值对。接下来,通过一张图来描述MapReduce的简易数据流模型,具体如下图所示。
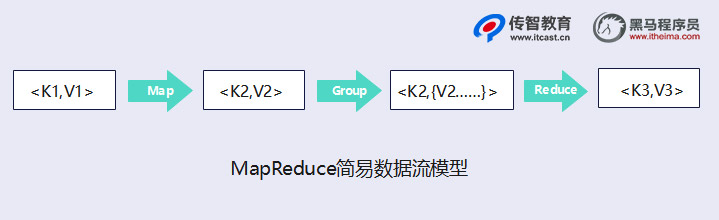
对于上图描述的MapReduce简易数据流模型说明如下:
(1)将原始数据处理成键值对形式。
(2)将解析后的键值对传给map()函数,map()函数会根据映射规则,将键值对映射为一系列中间结果形式的键值对。
(3)将中间形式的键值对形成形式传给reduce()函数处理,把具有相同key的value合并在一起,产生新的键值对,此时的键值对就是最终输出的结果。
这里需要说明的是,对于某些任务来说,可能不一定需要Reduce过程,也就是说,MapReduce的数据流模型可能只有Map过程,由Map产生的数据直接被写人HDFS中。但是,对于大多数任务来说,都是需要Reduce过程的,并且可能由于任务繁重,需要设定多个Reduce。例如,下面是一个具有多个Map和Reduce的MapReduce模型,具体如下图所示。
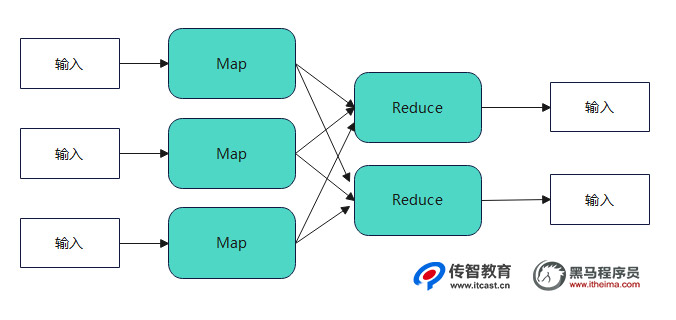
上图中演示的是含有3个Map和2个Reduce的MapReduce程序,其中,由Map产生的相关key的输出都会集中到Reduce中处理,而Reduce是最后的处理过程,其结果不会进行第二次汇总。
猜你喜欢:




















.jpg)